Speech Recognition with Deep Learning Toolkit for LabVIEW
- Alik Sargsyan

- Oct 25, 2018
- 3 min read
Updated: Aug 27, 2025

In this post, we would like to share the knowledge we acquired during participation in Kaggle competition. Although we didn’t win the competition the experience we had was worth it.
The project offered by Kaggle included a Speech Recognition problem that was supposed to be solved with Deep Learning algorithms. We thought this was a perfect opportunity to share our approach of tackling the challenge and conduct a demonstration of Deep Learning Toolkit by Ngene at the same time.
This blog post is organized in the following order:
Problem and dataset description
Insights on how Convolutional Neural Networks can be applied for Speech Recognition problems
Explanation of the main VIs of this specific project, namely Dataset Preprocessing:
Training
Deployment for test/inference
Dataset and the problem
The dataset is Speech Commands Datasets v0.001 released by TensorFlow. It includes 65,000 one-second-long utterances of 30 short words pronounced by thousands of different people. The task was to build an algorithm that can identify which specific word was pronounced in the audio sample.
Convolutional Neural Network classifier for spectrograms
As the waveforms which represent only time and amplitude of the pronounced words are almost the same, we have decided to convert those one-dimensional waveforms into two-dimensional spectrograms by including the third component that is the frequency of the signal. The differences between the signals are clearly expressed now.

CNN based classifiers which are one of the few successful techniques that are capable of classifying complex images have been chosen to be used in this specific problem, thus converting voice recognition problem into image classification. As a part of the data preparation process, we will need to convert the spectrograms of the signals into images to later feed them into the NN classifier for the training.
Dataset Preparation
The conversion of waveforms is done with help of Wave_to_STFT_PNG.vi(available as main VI in DeepLTK) which takes the path to the waveform dataset, converts all the .wav file into spectrograms and stores the .png images at the specified destination grouped into the folders based on the label(pronounced word). The user can also adjust the output resolution and STFT transformation parameters on the front panel.

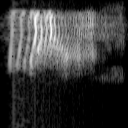
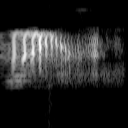
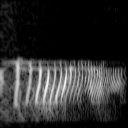
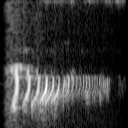
Some examples of converted spectrograms can be seen below.
Images where word "Five" is pronounced:


Images where word "On" is pronounced:

After finishing data preparation and having all spectrograms converted into images, we can train a standard CNN based classifier.
Training a CNN for image classification
For the training of CNN, we have built a special VI. It is very similar to the one for the MNIST classifier which comes with the toolkit's installer with some modifications in dataset reading and testing processes.
Deploying the trained model for inference.
For the inference we have two examples:
Speech_Rec_Test(file).vi - which predicts what word is pronounced in the wave file.
Speech_Rec_Test(microphone).vi - which continuously monitors the sound from microphone, and after detecting a sound above specified threshold predicts the word pronounced with 1 second of that event.

The project can be downloaded from our GitHub repository and additional instructions for running the VIs described above can be found on the front panel of each VI.
You can also watch the video post for a more detailed explanation.
In case of having any questions, please leave a comment below or contact us by sending an e-mail to info@ngene.co.









Comments